古籍OCR API已上线
为满足用户多样化、定制化OCR使用需求。现已上线API识别服务,通过申请获取token,通过编程等方式轻松定制化调用OCR服务,满足多样化场景需求。
本次除开通API服务外,还新增文本排版方向选择功能,在OCR功能、数字化功能中使用OCR识别服务可自由选择自动识别、竖排和横排三种识别模式。新增此功能用以解决现有模型在识别横竖排时判断不准确的问题,用户可根据自己的图像、PDF中文本排版方向,强制使用不同的识别模式,该识别模式决定图像识别结果中句子的方向和最终所有语句的排序。
API功能使用详细介绍:
一、申请API Token
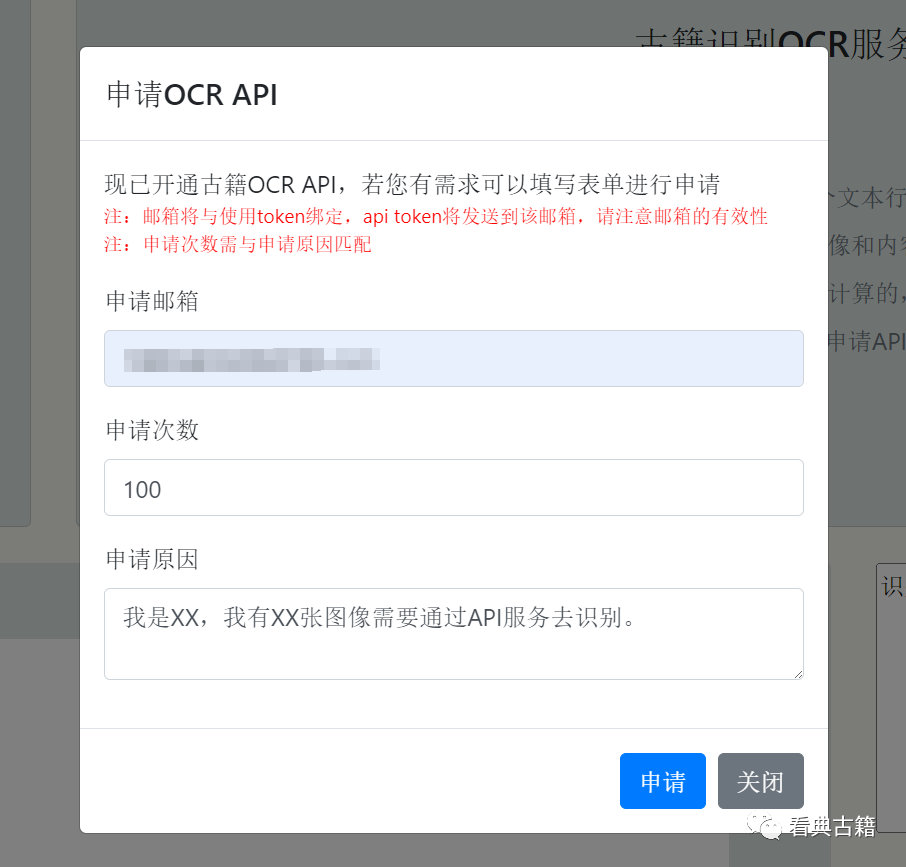
打开网站登录后在古籍OCR板块中,点击【申请API】,在弹窗中输入申请邮箱、申请次数(可用次数)以及申请原因,提交即可。

二、在右上角用户名处点击可以看到我的API页面入口
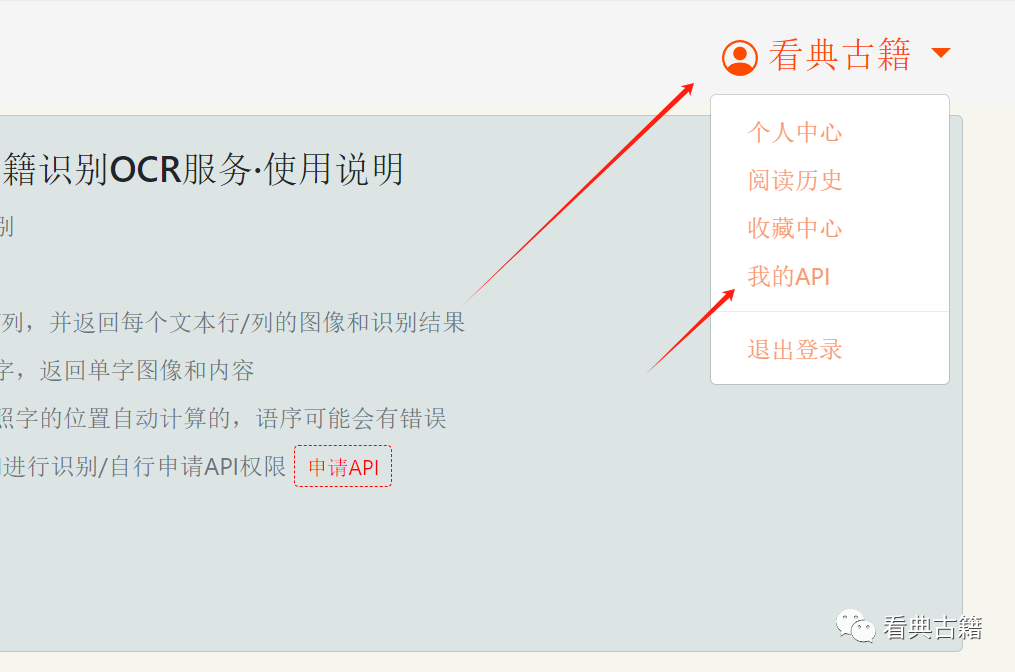

可以看到所有的API申请和每个API的激活情况,使用次数等信息
三、待管理员审核通过后API将会被激活,即可以调用使用OCR服务
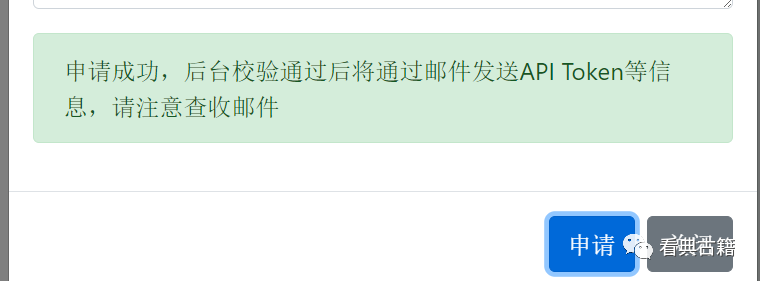
管理员将会给申请邮箱发送API申请申请成功/失败的邮件信息,请注意查收邮箱邮件。

四、API确认激活后可以调用在线识别服务
API调用文档如下:
接口地址:
1 | |
请求参数
参数名 | 是否必传 | 值 | 说明 | |
1 | image | 是 | 图像base64编码 | |
| 2 | token | 是 | 识别码 | |
| 3 | 是 | 申请token时使用的邮箱地址 | ||
| 4 | image_size | 否 | 图像长边缩放尺寸,0为不调整,默认为1024 | |
| 5 | char_ocr | 否 | 是否单字检测识别模式,默认为False | |
| 6 | det_mode | 否 | 'auto'/'sp'/'hp' | 可选自动判断文字排版方向、指定竖向排版识别、指定横向排版识别。默认为自动判断 |
| 7 | return_position | 否 | True/False | 是否返回文本行坐标/文字坐标,默认只返回语句列表 |
| 8 | return_choices | 否 | True/False | 若return_position为True时生效,默认为False |
响应参数,返回json格式数据:
通用参数
参数名 | 值 | 说明 | |
message | success/error | 识别状态,成功与否 | |
id | 请求id | ||
info | 与message相关联,成功为空,错误为具体错误信息 | ||
data | 数据参数 |
数据参数
参数名 | 值 | 说明 | |
width | 图像宽度像素 | ||
height | 图像高度像素 | ||
text_angel | 0/1 | 文字排版方向,0:横排,1:竖排 | |
text_angel_confidence | 文字排版方向置信度 | ||
text_lines | list | 识别文本行内容,语序与返回顺序一致 | |
texts | list | 汇总文本行文本 |
text_lines详情
参数名 | 值 | 说明 | |
position | [[x,x],[],[],[]] | 文本行位置坐标,四个点坐标 | |
text | 文本内容 | ||
words | list | 每个字符的内容 | |
以下为words内部内容 | |||
text | 文字内容 | ||
confidence | 识别置信度 | ||
position | [x1,y1,x2,y2] | 位置坐标,左上角与右下角两点矩形坐标 | |
choices | 候选字,可通过return_choices参数控制 | ||
det_confidence | 检测置信度 |
具体格式请自行调用API查看,若有任何问题或疑问可联系我进行反馈。
感谢阅读!