能力升级 | 古籍OCR再进一步
距离上一次古籍文字识别OCR更新已经过去了六个月,这段时间我们在不断优化OCR能力,提升在古籍图像上的文字检测和识别能力。本次更新主要有:提升语句检测和文字检测的精度、提升文字识别的准确率、字符库扩增、识别结果语序排序优化、古籍图像矫正(暂未上线)。
体验:https://www.kandianguji.com/ocr
一、 提升 语句 检测和文字检测的精度
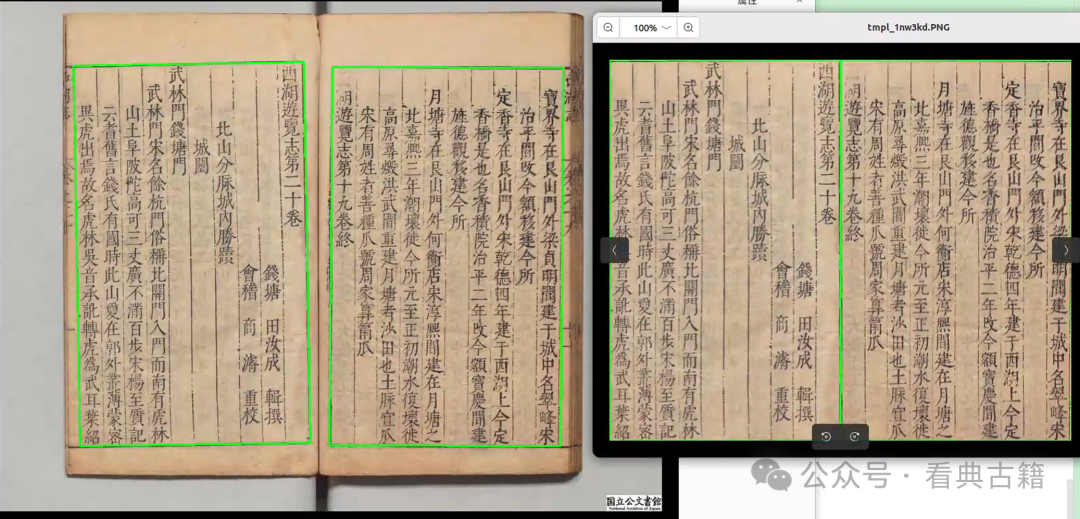
文字检测在整个文字识别流程中是第一步也是最主要的一步,检测的效果决定后面识别的效果,本次更新对于漏句、漏字效果有很大改善,支持的古籍图像也更加广泛,通过更精确地确定语句位置,系统能够更准确地识别文本内容,提高了整体的识别效率。

二、
字符库扩增
本次更新扩增字符库到17000+,包含常见文字、繁体字、异体字等绝大部分文字,字符库还在持续扩展中,之后的版本将支持更多中文字。
三、 提升 文字识别的准 确率
本次更新相较于上一版本有较大改进,识别效果更精确、识别速度更快。
0.5<蓝色<0.8;红色<0.5;黑色>0.8




四、 识别结果语序排序优化
本次更新对于古籍识别结果的顺序进行优化,按照从右到左,从上到下的主逻辑进行排序。
由于古籍版式更多,写法多样,结果排序目前效果还差一些,还需要进行优化完善。



五、 古籍图像矫正 (暂未上线 )
本功能主要针对古籍扫描后倾斜,透视变换等问题进行矫正,提取图像中文本区域,进行识别,图像矫正后可以提升OCR结果语序的准确率。
本功能在内测完成后将上线,将同步新增本功能的API。

除以上更新外,本次更新对文件服务器进行升级,对OCR服务器进行升级,相较之前服务稳定性增强,访问容纳量增大。
感谢您的阅读,如果您有任何疑问、意见或建议都可以私信我们或者在我们网站提交反馈!
看典古籍
2024年4月27日