使用教程·古籍数字化·PDF文件识别
本期介绍如何在 看典古籍 平台通过古籍数字化功能实现PDF文件的识别处理。
一、进入PDF文件识别功能页面
https://www.kandianguji.com/shuzihua?page_mode=pdf_file
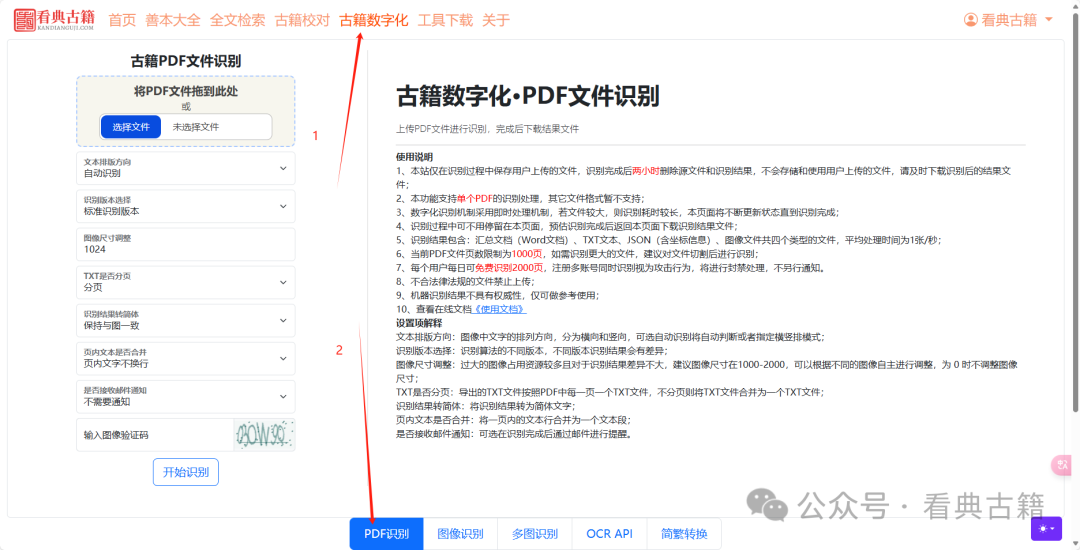
二、选择本地的PDF文件
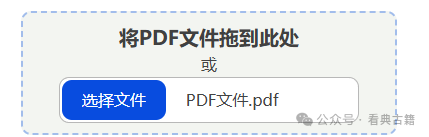
在左侧文件上传区域拖入本地PDF文件或点击在弹窗中选择PDF文件

三、设置处理参数
文本排版方向:图像中文字的排列方向,分为横向和竖向,可选自动识别将自动判断或者指定横竖排模式;
识别版本选择:识别算法的不同版本,不同版本识别结果会有差异;
图像尺寸调整:过大的图像占用资源较多且对于识别结果差异不大,建议图像尺寸在1000-2000,可以根据不同的图像自主进行调整,为 0 时不调整图像尺寸;
TXT是否分页:导出的TXT文件按照PDF中每一页一个TXT文件,不分页则将TXT文件合并为一个TXT文件;
识别结果转简体:将识别结果转为简体文字;
页内文本是否合并:将一页内的文本行合并为一个文本段;
四、输入图像验证码

验证码不区分大小写
五、创建任务
点击创建任务,即可在后台进行识别处理
六、下载结果
任务创建后在右侧会显示任务处理进度的信息
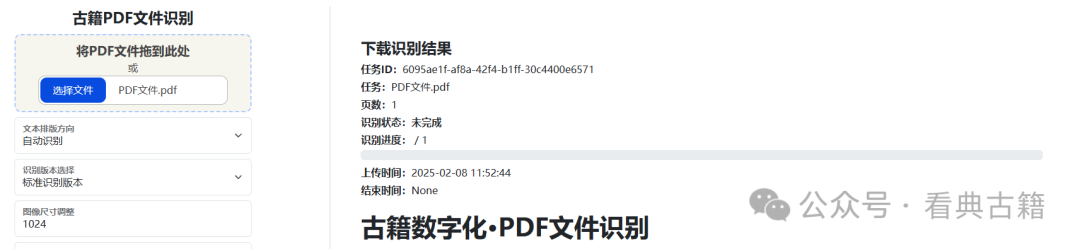

在处理完成后,识别状态将为:完成,表示PDF已识别完成,可以下载识别结果了。
按钮解释:
- 下载汇总文档
下载Word格式的结果文件

压缩包中共有两个文件:换行和不换行的区别,表示每一页页内文本行是合并还是分开展示,区别如下:
不换行的情况下:xxxxyyyy
换行的情况下:
xxxx
yyyy
- 下载TXT

压缩包中将存放每一页的文本内容,每一页会有换行与不换行之分,按照需要提取文件即可。
- 下载JSON

压缩包中存放每一页的JSON数据,json数据将包含图像宽高、每一个文本行的位置信息、每一个字的位置信息、候选字等数据。
- 下载全部结果
压缩包中将包含每一页的图像、Json、Txt已经全文档的汇总文档等文件。
以上就是看典古籍平台上关于 古籍数字化·PDF文件识别的使用教程。