使用教程·古籍数字化·图像识别
本期介绍如何在 看典古籍 平台通过古籍数字化功能完成 古籍图像上文字的识别提取。
一、进入图像识别功能页面
https://www.kandianguji.com/shuzihua?page_mode=img_file
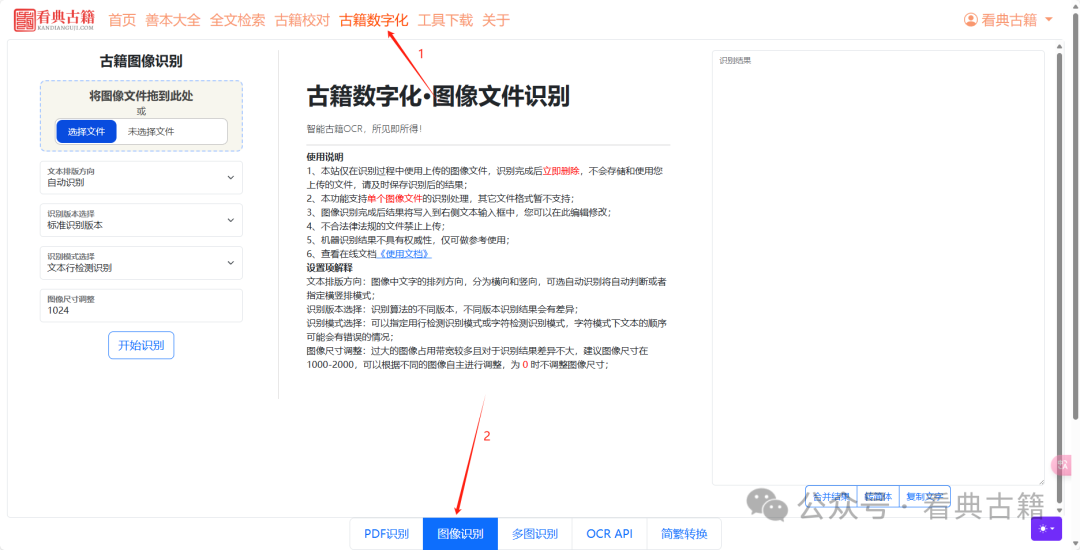
二、选择要识别的图像文件
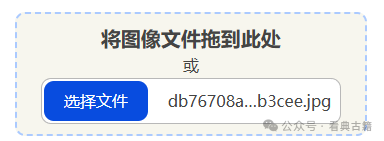
在左侧文件上传区域拖入本地图像文件或点击在弹窗中选择图像文件
三、设置识别参数
文本排版方向:图像中文字的排列方向,分为横向和竖向,可选自动识别将自动判断或者指定横竖排模式;
识别版本选择:识别算法的不同版本,不同版本识别结果会有差异;
识别模式选择:可以指定用行检测识别模式或字符检测识别模式,字符模式下文本的顺序可能会有错误的情况,两种模式的区别如下:
行检测识别模式:
字符检测识别模式:

图像尺寸调整:过大的图像占用带宽较多且对于识别结果差异不大,建议图像尺寸在1000-2000,可以根据不同的图像自主进行调整,为 0 时不调整图像尺寸;
四、开始识别
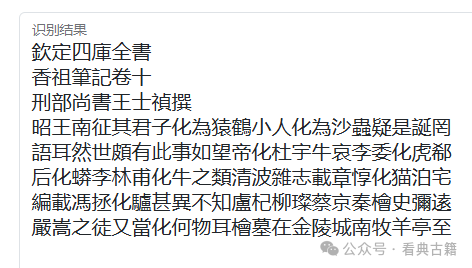
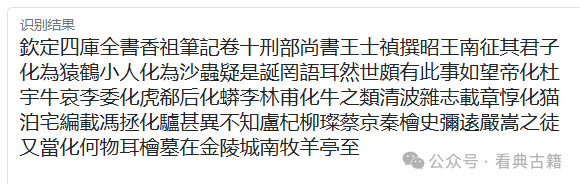
点击开始识别按钮,识别引擎将提取并识别图像上的文字内容,将识别结果写入到识别结果中

点击识别结果底部的功能按钮可以执行相应的功能:
合并结果:将分句文本合并为一段
转简体:将繁体的文字转为简体文字

复制文字:点击一键复制结果。
五、批量识别
在实际使用中,大部分用户希望可以批量识别图像文件,可以在古籍数字化平台中使用 多图识别 功能,具体操作如下:
进入多图识别功能页面:
https://www.kandianguji.com/shuzihua?page_mode=image_files
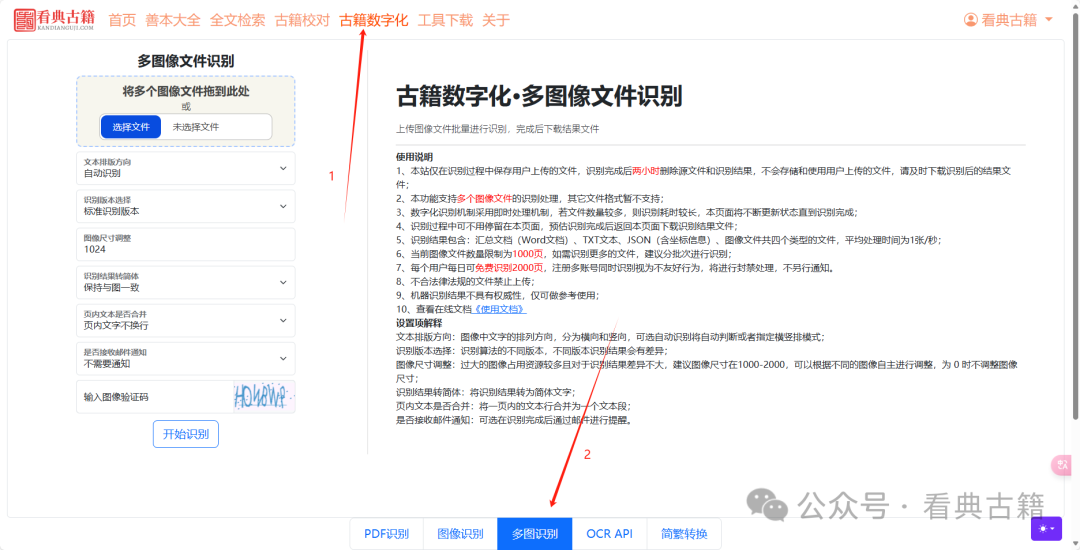
和PDF识别功能的区别只有上传文件的区别,可以上传多张图像进行处理,识别结果和PDF识别功能一致,可以参见PDF识别使用教程使用教程·古籍数字化·PDF文件识别 。
以上就是看典古籍平台上 古籍数字化·图像文件识别功能 的使用教程。
相关教程